
本文先对Table的访问局部性进行测量,然后再基于这个特性来指导优化脚本的运行性能。
测量准备
计时函数
Lua标准库中带的计时函数的精度不够高,这里还是使用上篇文章中提到的Linux sys/time 库函数gettimeofday来提供微妙(us)级别的计时精度。与之前不同的是,本次因为要测量整个循环过程的耗时,所以不能将计时加到Lua Table库函数的单次操作中。这里打算扩展Lua os标准库,LuaJit同理:
// Lua 5.1.5 file: loslib.c
double GetClock();// return gettimeofday timeval.tv_usec
static int os_clock_us(lua_State *L)
{
lua_pushnumber(L, (lua_Number)GetClock());
return 1;
}
// e.g. local clock_us = os.clock_us
// e.g. local start = clock_us()
// e.g. -- do something...
// e.g. local finish = clock_us()
// e.g. print(finish - start)
static const luaL_Reg syslib[] = {
{"clock", os_clock},
{"clock_us", os_clock_us},
// other functions...
{NULL, NULL}};
测试环境
本文重点关注Lua脚本在手机上的表现,虽然在测试过程中有测量PC环境的数据,但是本文不再表现其具体结果。
手机的测试环境:
- 魅族MX16th Android 8.1.0
- CPU 高通845 L1: 64KB data cache; L2: 256KB L3: 2MB;[^1] [^2]
- 8G RAM
交叉编译环境
- NDK版本 r21-linux-x86_64,运行环境WSL Ubuntu 18
- NDK ABI version 21
- 目标平台AArch64
- 工具链:llvm/predbuilt/linux-x86_64/bin/aarch64-linux-android-*和aarch64-linux-android21-clang
编译liblua.so和libluajit.so的主要困难在于,把原生的Makefile文中指定的工具链和路径宏改到NDK中不是很方便,需要手动修改每一处编译命令。
打包环境
- Unity 2019.3.11f1
- IL2CPP Release
- ARMv7, ARM64
- Android 5.0 API level 21
- .NET Standard 2.0
C#调用Lua
这里没有用现成tolua或xlua插件调用Lua,而是直接编译原生Lua5.1.5和LuaJit代码并导入到工程中。然后仿照xLua的导入了最小启动Lua环境的API。除了启动Lua环境外,另一个重点是要重定向Lua的print函数。
// test.cs
L = luaL_newstate();
luaL_openlibs(L);
IntPtr panic = Marshal.GetFunctionPointerForDelegate(new LuaDelegate(Panic));
lua_pushcclosure(L, panic, 0);
lua_setfield(L, LUA_GLOBALSINDEX, "panic");
IntPtr print = Marshal.GetFunctionPointerForDelegate(new LuaDelegate(Print));
lua_pushcclosure(L, print, 0);
lua_setfield(L, LUA_GLOBALSINDEX, "print");
Lua环境启动后直接使用luaL_loadstring(L, script);和lua_pcall(L, 0, -1, 0);调用Lua脚本。
遍历数组和字典的差异
测试用例主要是计算数组中Vector3与主角的距离的平方:
local function SqrDistance(x1,y1,z1, x2,y2,z2)
local diff_x = x1 - x2
local diff_y = y1 - y2
local diff_z = z1 - z2
return diff_x*diff_x + diff_y*diff_y + diff_z*diff_z
end
for i = 1, length do
local pos = vec[i]
SqrDistance(hx,hy,hz, pos.x,pos.y,pos.z)
end
Lua Table中Array和Hash部分虽然都是连续内存块,但是Lua Table Hash部分在实现next遍历函数中还是需要查询与确定当前Key的索引。因此Lua Table的Array和Hash遍历还是有性能差异。
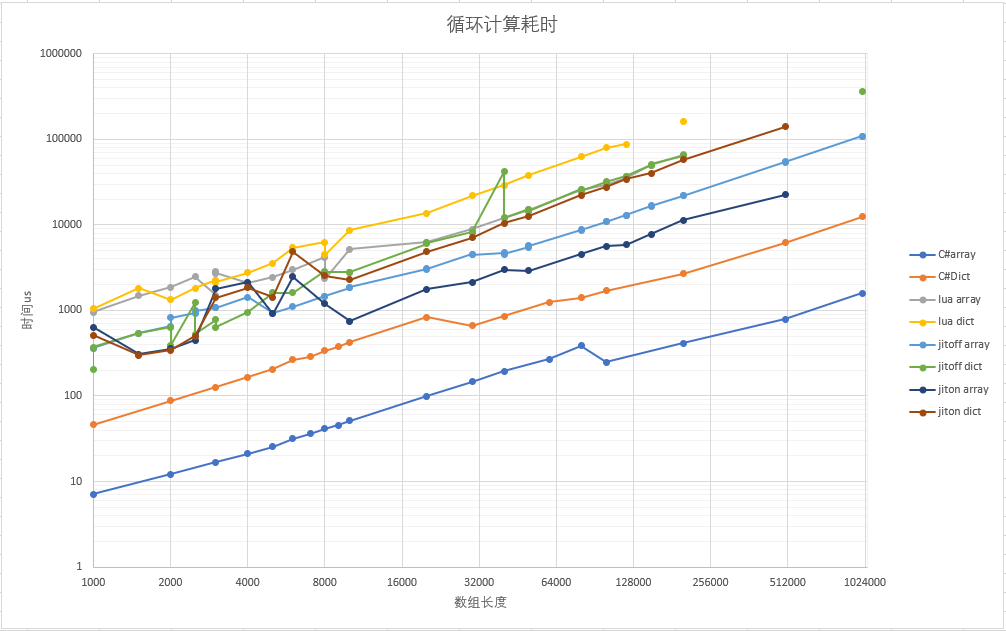
上图列举了Lua5.1、LuaJit on、LuaJit off和C#中的性能表现。在同一虚拟机和环境中,Array遍历比Hash遍历快3-4倍甚至更高,但是在数据量小,能被L1缓存命中时差距不明显。
同时图中有一些点呈现逆趋势的状态,这是当前数据尺寸刚好启动了下一级缓存,以后详细分析这一违反直觉的现象。
减少Lua Table产生的间接引用
根据上篇文章分析,Lua Table中的Array和Hash是连续的内存块,但是如果Lua Table中的项又是一个Table,那么这样还是会破坏访问的局部性
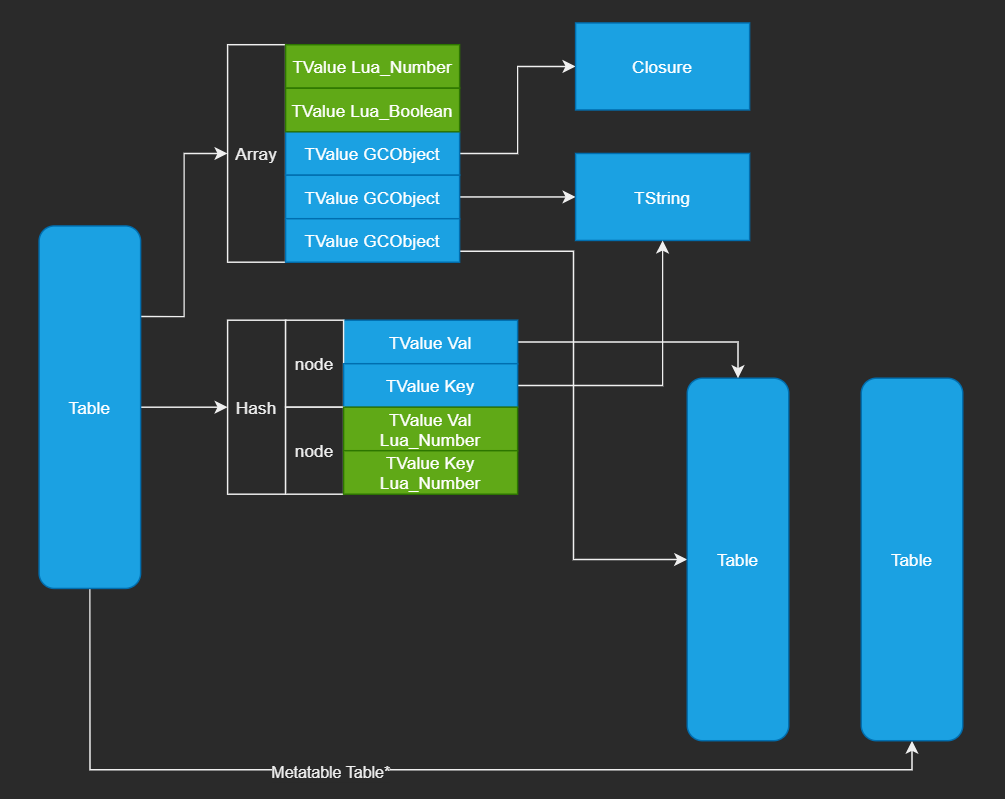
形如下列定义就至少产生了三次间接引用,如果Table的key是GCObject类型的话,引用次数则更多!
local players_pos = { {x = 1, y = 2, z = 3}, ...}
良好的局部性会很好的利用多级缓存加速程序运行。反之,多次间接引用可能造成缓存频繁丢失,甚至造成缓存颠簸,减慢程序运行。为了利用局部性优化,这里 不得不暗搓搓的又提起ECS 采用SOA(Struct of Array)结构。[^4]
local posx = {1, ...}
local posy = {2, ...}
local posz = {3, ...}
for i = 1, length do
SqrDistance(hx,hy,hz, posx[i],posy[i],posz[i])
end
甚至可以更进一步
local pos = {1,2,3, ...}
local iy,iz = 2, 3
for i = 1, length * 3, 3 do
SqrDistance(hx,hy,hz, pos[i],pos[iy],pos[iz])
iy, iz = iy + 3, iz + 3
end
然而根据实测,第二种写法与第一种写法差别很小,甚至一不留神还会写出性能稍差的情况(查看字节码可以看到加法计算插入到了GETTABLE计算中):
local pos = {1,2,3, ...}
for i = 1, length * 3, 3 do
SqrDistance(hx,hy,hz, pos[i],pos[i+1],pos[i+2])
end
下图是测试结果:
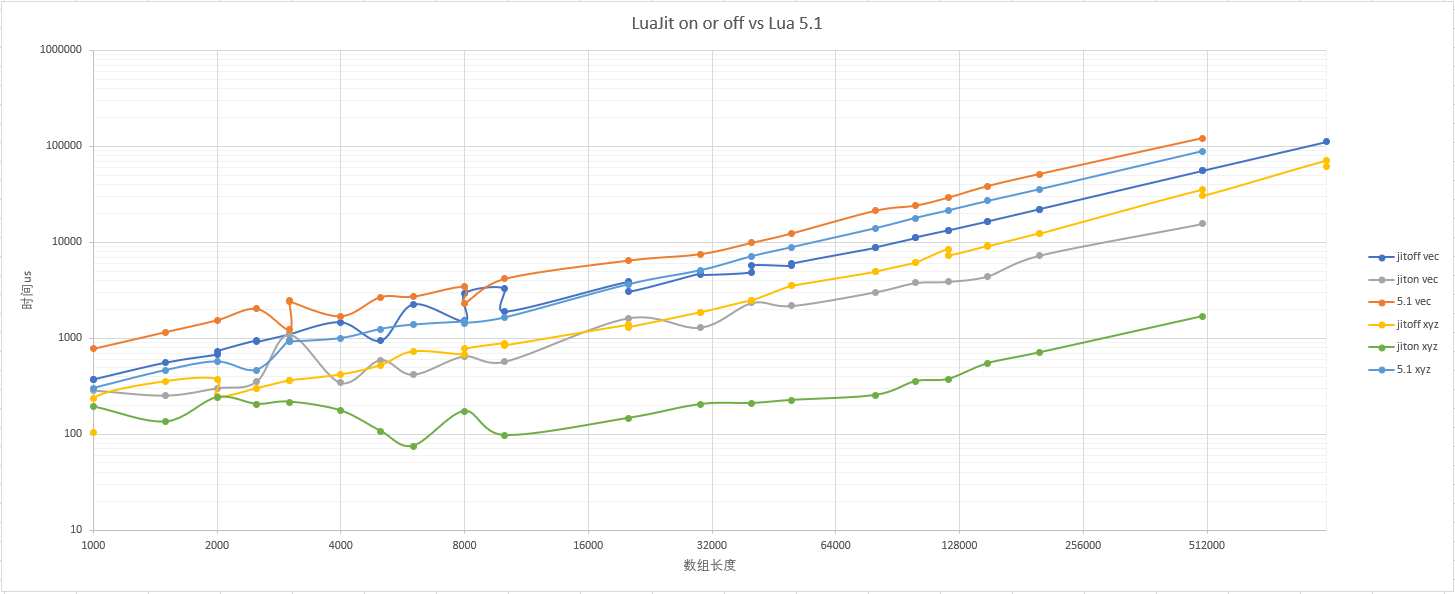
图例中vec表示采用vec.x,vec.y,vec.z形式测试用例,xyz表示采用pos[ix],pos[iy],pos[iz]形式测试用例。图中测试结果表明,良好的局部性可以提供2~5倍性能提升,而且完全被L1命中时表现更好。LuaJit开启Jit后甚至可以提升一个数量级。
SOA可以提供更为紧凑的内存
大量使用Table模拟Struct时,一方面会创建太多GCObject而拖慢GC标记过程,另一方面Table又会浪费大量内存,产生非常多的内存碎片。
n * (sizeof(Table)+sizeof(Node * m)) + sizeof(Table) + sizeof(TValue * n)
如果采用SOA形式就可以在避免构建大量Table的同时减少内存浪费。
m * sizeof(Table) + sizeof(TValue * n)
如果没有办法得到连续的Index来构建Array,使用Hash的话也是是紧凑的布局(Key和Value需要TValue类型而不是GCObject):
local key = id
local pos = {[key] = 1, [key + 1] = 2, [key + 2] = 3, ...}
它的大小是:
m * sizeof(Table) + sizeof(Node * n)
Table Array和Node是整块内存,在空间增长替换时会及时释放,在引用的过程中也会有较好的局部性。
SOA的使用困境
SOA固然能提供比较好的局部性,但是编写过程相对复杂。如果提供封装好的自动化生成函数,那么又引入了上值(UpValue)和函数(Closure)的间接引用,从而在一定程度上破坏局部性。比如下面封装形式:
local function SetTuple3(t, n1, n2, n3)
local v1, v2, v3 = {},{},{}
t[n1], t[n2], t[n3] = v1, v2, v3
return function(index)
return v1[index],v2[index],v3[index]
end,
function(index, x, y, z)
v1[index],v2[index],v3[index] = x, y, z
end
end
local stores = {}
local Get, Set = SetTuple3(stores, 'x', 'y', 'z')
for i = 1, length do
Set(i, RandomPos())
end
在业务逻辑中可以直接使用Get和Set函数来操作具体的数组项,例如:
for i = 1, length do
SqrDistance(hx, hy, hz, Get(i))
end
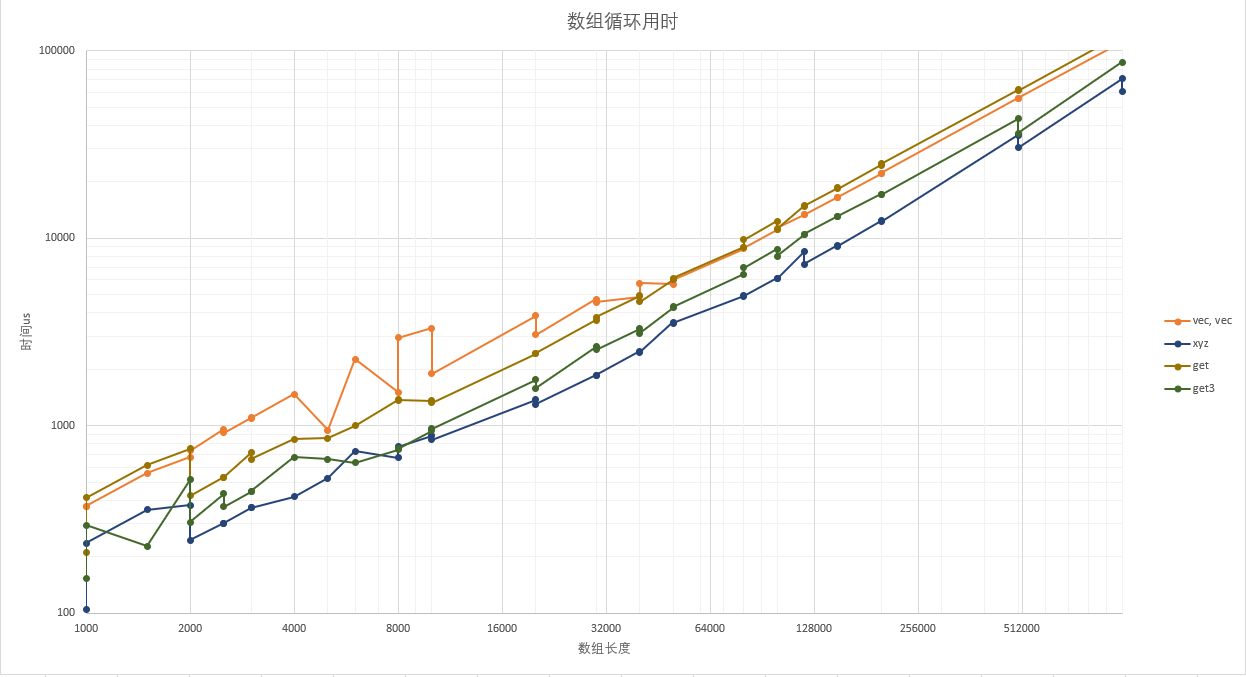
由上面测试结果可以看到,使用SOA封装的Get函数性能位于完全SOA形式和常规形式之间。小数据量(<32k * 3 * 16B)时有2倍提升,数据量大时趋势反转,造成这个现象一部分原因是UpValue太大导致缓存没有命中。get3函数是对索引约束以后的测试结果,在实际业务中可能不太实用,但可以作为一个性能上限:
local function SetTuple3(t)
return function(index)
local index2, index3 = index + 1, index + 2
return t[index],t[index2],t[index3]
end,
function(index, x, y, z)
local index2, index3 = index + 1, index + 2
t[index], t[index2], t[index3] = x, y, z
end
end
local Get, Set = SetTuple3(stored)
-- Set loop
for i = 1, length * 3, 3 do
SqrDistance(hx, hy, hz, Get(i))
end
面向对象是Lua工程中的最佳实践吗?
在业务逻辑中使用Lua,都会构建一个或实现简单或实现复杂的面向对象方案:通过使用setmetatable来模拟多态和继承关系。面向对象作为一个工程实践,话题太大不好讨论,也不好定量分析。这里约束一下范围,为了高性能的使用Lua:
- 我们一定需要模拟面向对象来实现多态和继承么?
- 为重用代码、提供抽象而使用metatable从而破坏的可读性和访问局部性是否值得?
通过Mix In或者直接定义相关功能函数实现多态
作为一个动态类型的脚本语言,多态是天然存在的。Lua Table不需要模拟继承任何接口而直接判断是否拥有某个Key值的函数就可以确认它是否有相应能力,而不用去背负静态语言中的语法包袱。比如:
local Unit = GetUnitBySomeLogic(entity_data, ...)
if Unit.Move then
-- a movable unit, like monster, player
Unit.Move(entity_data, delta_time)
end
上面例子中的Move函数可以是直接定义在具体Monster中的函数(覆盖了默认逻辑),可以是从NPC中Mix in的(代码复用)。
显式引用抽象模块的函数,而不是通过Metatable隐式引用
Metatable虽然灵活功能强大,但是它带来了大量的心智负担。使用者不能在短时间内判断出当前函数的来源。比如应当尽量避免使用隐式引用的形式:
-- HostPlayer.lua
local HostPlayer = EntityPrefab:extends()
function HostPlayer:CreateChild(...)
end
function HostPlayer:GetWeapon(...)
end
-- other define...
return HostPlayer
-- Scene.lua
local player = HostPlayer.new(...)
player:setData(data)
player:show()
player:CreateChild(...)
要显示引用,表明函数来源:
-- Scene.lua
local player = HostPlayer.new(...)
Object.setData(player, data)
EntityRes.show(palyer)
HostPlayer.CreateChild(player, ...)
除此之外,因为显示引用不用多次Metatable查找与跳转,所以逻辑的局部性更优秀,缓存命中和分支预测效果变好,从而得到性能提升。
使用Metatable的性能表现
测试用例见附录,下图为测试结果:
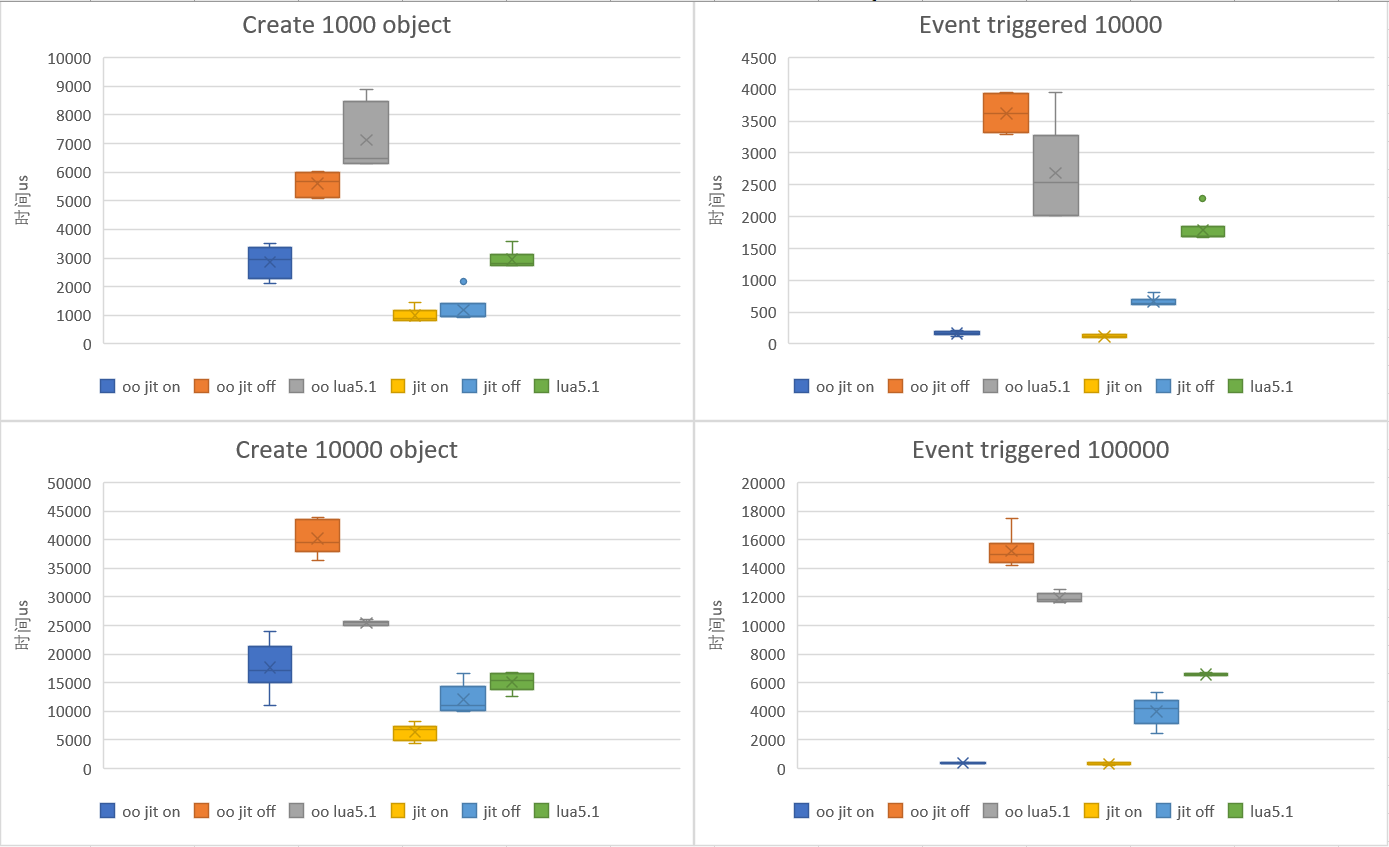
图例中OO*表示使用Metatable模拟面向对象的调用耗时,左侧两幅图为创建对象耗时,右侧两幅图为一个对象调用n次抽象函数耗时。图中方块数据表示耗时的上下界;中心x表示平均值;细线表示偏离值。
从测试结果可以看到,Metatable带来了极大的性能开销!
结论
在Lua的使用过程中,尽量保证逻辑的访问局部性,可带来可观的程序性能提升。
- 使用SOA Helper模板函数可以在编写便利和程序性能方面提供一个相对平衡的折中。
- 使用MixIn来避免OO实现逻辑多态可以同时提供良好的可读性和优秀的性能。
附录
OO和MixIn测试用例
OO测试用例
local object = {}
function object:extends()
local class = {}
setmetatable(class, {__index = self})
return class
end
function object:new()
local new_one = {}
setmetatable(new_one, {__index = self})
new_one:onNew()
return new_one
end
function object:onNew()
end
local Entity = object:extends()
function Entity:setData(data)
end
function Entity:addCom(com)
end
function Entity:popEvent(event_type, data)
end
local EntityRes = Entity:extends()
function EntityRes:onNew()
self.isEnable = false
end
function EntityRes:show()
self:startLoad()
self:onResEnable()
self:onEnable()
self:onShow()
end
local EntityPrefab = EntityRes:extends()
function EntityPrefab:startLoad()
--self.resObj = LoadObject()
end
function EntityPrefab:onResEnable()
--self.resObj:SetActive(true)
end
local EntityPlayer = EntityPrefab:extends()
function EntityPlayer:onEnable()
self.com1 = self:addCom(1)
self.com2 = self:addCom(2)
self.com3 = self:addCom(3)
end
function EntityPlayer:onShow()
--self.com1:show()
--self.com2:show()
--self.com3:show()
end
local length = {0}
local clock_us = os.clock_us
local entities = {}
local start = clock_us()
for i = 1, length do
local player = EntityPlayer:new()
player:setData()
player:show()
entities[i]=player
end
local finish = clock_us()
print(string.format('Create %s entities cost:%sus', length, finish - start))
start = clock_us()
local entity = entities[1]
for i = 1, length * 10 do
entity:popEvent()
end
finish = clock_us()
print(string.format('1 entity %s popEvent cost:%sus', length * 10, finish - start))
MixIn测试用例
local function MixIn(src, des)
for k, v in pairs(src) do
des[k] = v
end
end
local Entity = {}
function Entity.setData(left, right)
end
function Entity.addCom(data, com)
end
function Entity.popEvent(data, event_type, event_data)
end
local EntityRes = {}
function EntityRes.show(depend, Data)
depend.startLoad(Data)
depend.onResEnable(Data)
depend.onEnable(Data)
depend.onShow(Data)
end
local EntityPrefab = {}
function EntityPrefab.startLoad(data)
--data.resObj = LoadObject()
end
function EntityPrefab.onResEnable(data)
--data.resObj:SetActive(true)
end
local EntityPlayer = {}
MixIn(Entity, EntityPlayer)
--MixIn(EntityRes, EntityPlayer)
MixIn(EntityPrefab, EntityPlayer)
function EntityPlayer.onEnable(data)
data.com1 = EntityPlayer.addCom(data, 1)
data.com2 = EntityPlayer.addCom(data, 2)
data.com3 = EntityPlayer.addCom(data, 3)
end
function EntityPlayer.onShow(data)
--data.com1:show()
--data.com2:show()
--data.com3:show()
end
local length = {0}
local clock_us = os.clock_us
local entities = {}
local start = clock_us()
for i = 1, length do
local player = {}
EntityPlayer.setData(player)
EntityRes.show(EntityPlayer, player)
entities[i]=player
end
local finish = clock_us()
print(string.format('Create %s entities cost:%sus', length, finish - start))
start = clock_us()
local entity = entities[1]
for i = 1, length * 10 do
EntityPlayer.popEvent(entity)
end
finish = clock_us()
print(string.format('1 entity %s popEvent cost:%sus', length * 10, finish - start))
参考
- [1] 高通骁龙组件列表
- [2] ARM Cortex-A75
- [3] LuaJit Android install
- [4] Struct of Arrays